Preparing a Gaussian State in the Symmetrical Domain

Explanation of Our Solution at MIT iQuHACK
Introduction
In this blog post, I will explain the solution of our team to the Classiq track at MIT iQuHACK 2025, including why it works and how it scales.
Gaussian state preparation is essential for simulating physical systems and tackling problems in quantum chemistry, machine learning, and optimization. Gaussian states, characterized by their Gaussian-shaped wavefunctions, are powerful tools for encoding probability distributions and modeling quantum systems.
With the scaling of quantum hardware, achieving efficient and precise Gaussian state preparation could improve the costs of quantum algorithms and enhance impactful applications like option pricing in finance, molecular simulations in quantum chemistry, and data analysis in machine learning, among others.
At the competition, our challenge was to prepare a Gaussian state in the symmetrical domain
using a quantum circuit. The target state is defined as:
with
Here, (represented by EXP_RATE in our code) controls the decay of the Gaussian, and the domain discretization is determined by the resolution variable. Our task was to design a quantum circuit that not only achieves a small mean squared error (MSE) compared to the ideal Gaussian state but also scales efficiently as the resolution increases.
There are of course many solutions to this problem. For example, the easiest way is to first prepare a Gaussian state as an amplitude list of length (where is the number of qubits or resolution), then encode this list of amplitudes into the state vector using amplitude encoding. However, this method is costly, requiring complexity in the worst case scenario. Another method might be using Hamiltonian simulation with trotterization to calculate the exponentila part of the Gaussian, although it results in a true Gaussian, it is also pretty costly. Our solution is not perfect — it only approximates the Gaussian to an extent, but this approximation is good enough for the MSE error and most importantly, it scales almost linearly to the resolution or number of qubits, i.e. complexity.
Our Solution
Our solution is based on two key steps: first, preparing a state using RY rotations that encodes an exponential factor on each qubit, and second, applying the Quantum Fourier Transform (QFT) to convert that state into one with a Gaussian amplitude distribution.
First Step
When we apply an RY gate with angle to a qubit initially in , we obtain
The unitary gate matrix of the RY gate is
In our code, for each qubit indexed by we set
with
Thus, for the th qubit,
Using the trigonometric identities and , with , we find
For large , is very small, so the amplitude in is approximately
By applying these rotations to each of the qubits, the overall state becomes the tensor product
When this state is expressed in the computational basis, a basis state (with written in binary as where each ) has amplitude
Because , the amplitude is a product of factors that decay exponentially with . This product structure means that the probability distribution over appears as a steep exponential drop in the contributions of higher-index qubits rather than as a smooth Gaussian curve. This is shown in the figure below (only the first few amplitudes are shown):

Second Step
The next step is to apply the QFT, which acts on computational basis states as
with . After applying the QFT, the final state becomes
where
We can express the sum over in terms of the binary digits . Since is a product over qubit contributions, the sum factorizes, and we have
Substituting the approximate forms for and , this becomes
In the large- limit and with appropriate scaling of , the sum over approximates the discrete Fourier transform of a Gaussian function. It is a well-known fact that the Fourier transform of a Gaussian is another Gaussian:
which implies that the amplitudes in the Fourier basis take the form
up to normalization and a rescaling of parameters, where . Thus, although the original state in the computational basis exhibits an exponential decay coming from the product of bitwise factors, the QFT’s property of transforming Gaussians into Gaussians yields a smooth Gaussian distribution in the computational basis after applying QFT. Showing this transformation visually, the amplitudes after QFT are:
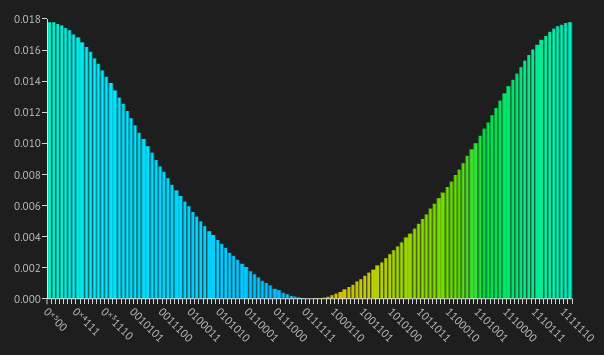
Note that the Gaussian is "inverted". To turn it back to a normal Gaussian, we can apply the X gate on the 0th qubit. The final result is:
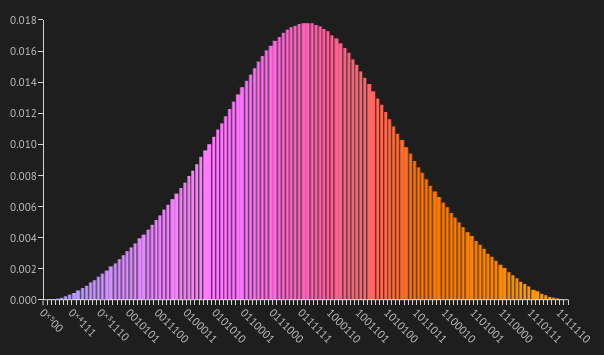
Using the method described above, we can reach a MSE error of .
The overall circuit is:

Scalability of Our Solution
The Phase 2 of the challenge is to maximize the scalability of our solution, i.e. make our solution works at the highest resolution with the least number of gates possible. The bottleneck of our solution described above was the QFT part, the number of gates in a regular QFT grows quadratically as the number of qubits increases:
We observed that the gate angles of the CPhase gates used in QFT decreases exponentially! The gate angle for the CPhase gate with layer number and qubit number is
When there are many qubits, the majority of the gate angles often become very small (e.g. less than ), which have negligible effects on the overall state vector. Therefore, we pruned any gates with angle smaller than a threshold as shown in the diagram below:
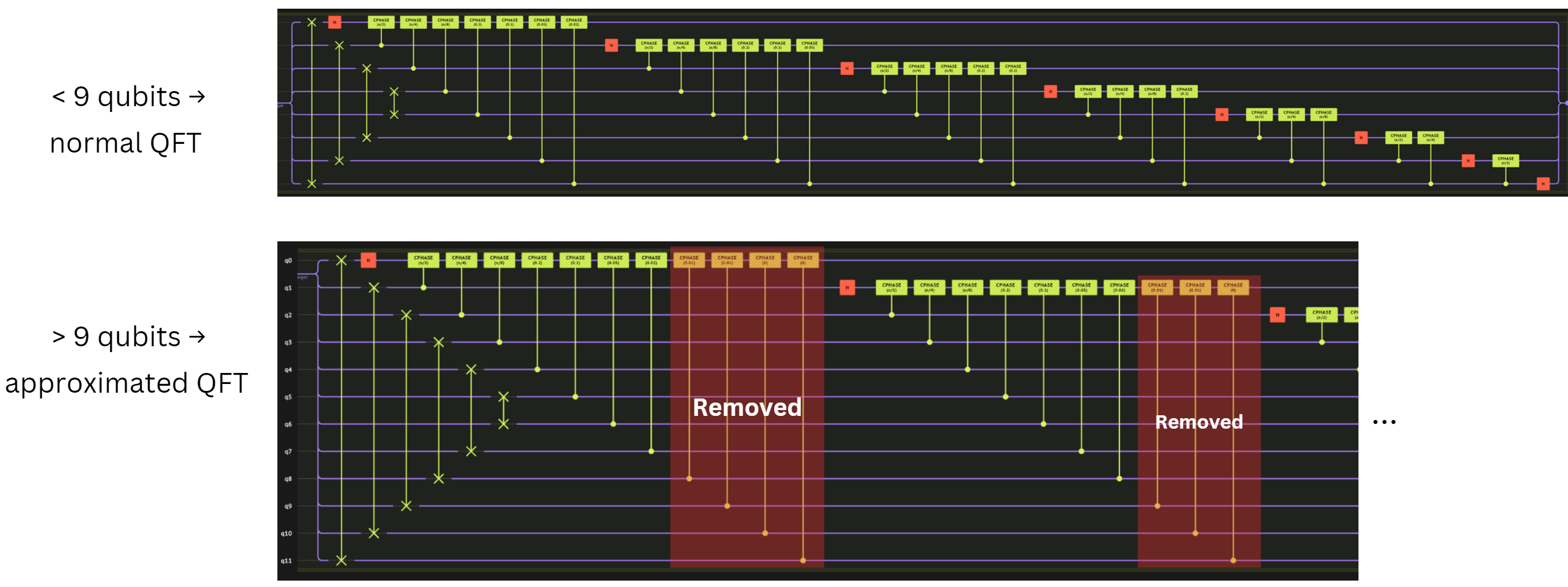
Now the number of gates in the approximated QFT with qubit number and is
We did an experiment to compare the effect of different choices of with 18 qubits (resolution = 18), below is a table summarising the results:
| Number of CX Gates | MSE error | |
|---|---|---|
| 293 | ||
| 245 | ||
| 153 |
We chose in our final submission for a balance of complexity and accuracy. The figure below shows the ratio between the number of CX gates and the resolution, which can be seen that the relation becomes linear if the resolution is large enough.
Here is an additional table summarising another experiment that compares the difference in MSE error when we change the resolution from 5 to 18 ():
| Number of CX Gates | MSE error | |
|---|---|---|
| 28 | ||
| 70 | ||
| 140 | ||
| 191 | ||
| 245 |
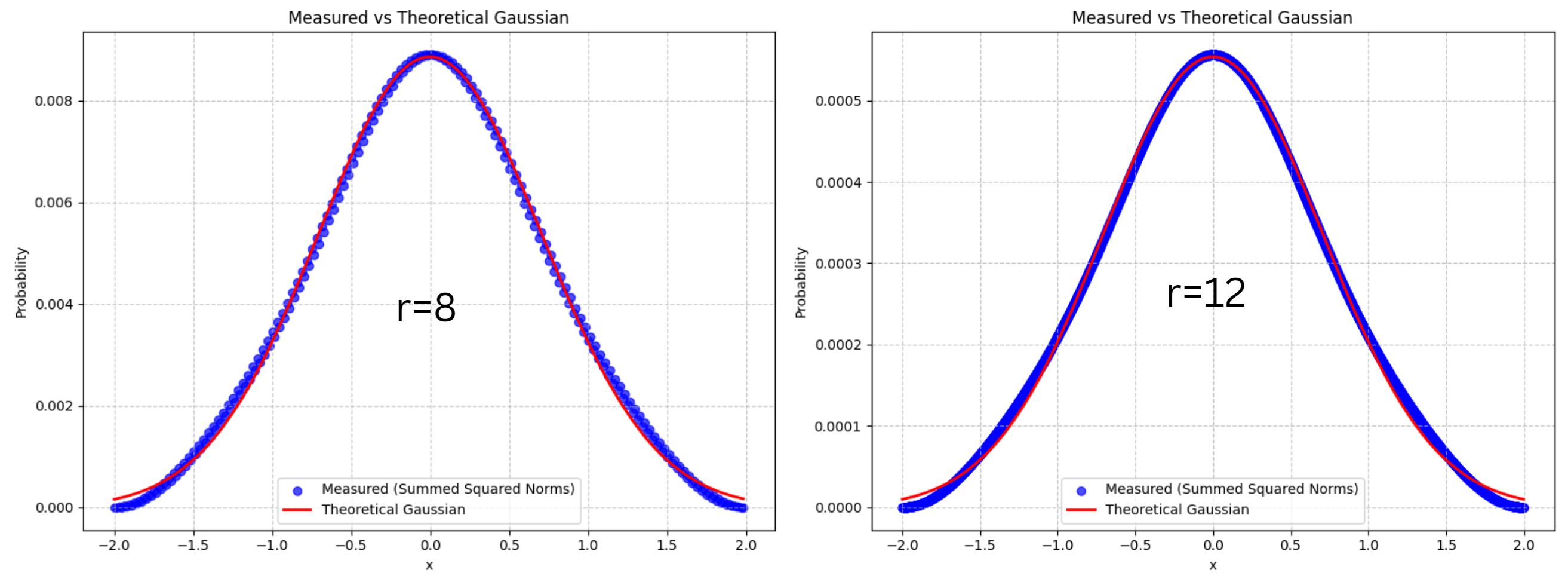
The MSE decreases as the resolution increases. This is because the overall probability scale is smaller when resolution is higher, leading to decreasing MSE. The Gaussian is also more fine-grained as resolution increases, as shown in the following figure:
Code of Our Solution
Below is the code we used for submission. It implements the two-step approach (product-state preparation + approximate QFT) and demonstrates how gate pruning is applied:
def create_solution(resolution: int):
fraction_digits = resolution - 2
EXP_RATE = 1
import math
@qfunc
def single_X(x_arr: QArray[QBit]):
X(x_arr[0])
@qfunc
def prepare_state(q: QArray[QBit]) :
for i in range(resolution):
exponent = (i ** 2)/(-2 * (EXP_RATE / math.sqrt(5)) ** 2)
angle = 2.0 * math.atan(math.exp(exponent))
if angle > 1e-6:
RY(angle, q[i])
CRY(-math.pi/42, q[0], q[1]) # a small "hand-tuned tweak"
@qfunc
def approx_qft(target: QArray[QBit]):
for i in range(resolution // 2):
SWAP(target[i], target[resolution - i - 1])
for j in range(resolution):
H(target[j])
for k in range(j+1, resolution):
theta = 2 * math.pi / (2 ** (k - j + 1))
if theta > 1e-2: # 9 qubits
CPHASE(theta, target[k], target[j])
@qfunc
def prepare_gaussian(x: QNum):
prepare_state(x)
approx_qft(x)
single_X(x)
return prepare_gaussian
Discussion and Future Work
Our pruning strategy for the QFT threshold was largely heuristic. Further adjusting (either making it adaptive to local circuit conditions or tuning it per qubit layer) may unlock even better trade-offs between gate count and fidelity. An in-depth exploration of different pruning schedules could systematically find the best thresholds for specific MSE targets.
Additionally, while our approach was tested in noiseless simulations, real devices inevitably introduce errors. Testing under realistic noise models (e.g., depolarizing or amplitude-damping channels) will help identify how robust the approximate QFT and the initial product-state preparation are in practice. We plan to run the circuit on a real quantum computer to gauge the impact of gate errors, crosstalk, and qubit decoherence.
Finally, Gaussian states have broad relevance to quantum machine learning (QML), e.g., for encoding continuous data distributions, generating feature maps, or performing kernel-based methods on near-term hardware. A natural next step is to investigate how well our circuit-based Gaussian preparation integrates into QML workflows, particularly in tasks such as clustering or dimensionality reduction. Improved scalability and resilience against hardware noise would make this approach more appealing for real-world QML applications.
Conclusion
We have presented an approach that efficiently prepares a Gaussian state in the symmetrical domain using a circuit of nearly linear complexity. By applying a simple product‐state preparation followed by an approximate QFT with pruning, we achieve a low MSE while keeping the gate count under control. This technique can be extended or refined for many practical tasks that rely on Gaussian states, especially as quantum hardware scales to higher qubit numbers.
Acknowledgements
We thank MIT and Classiq for organizing MIT iQuHACK 2025, and we extend our gratitude to the mentors and judges for their invaluable guidance and support throughout the competition.